Text Mining in HR) 나한테는 있는데 너한테는 없는 것
텍스 분석 in HR
텍스트 분석을 하는 이유는 주어진 문서를 정량적으로 이해하는 것이다.
HR 맥락에서 대표적인 텍스트 데이터 중 하나인 평가 의견을 중심으로 살펴보자.
평가의견은 S, A, B, C 등으로 직원의 성과에 따른 등급을 부여하면서 뭘 특별히 잘해서 S등급을 주었는지, 아니면 뭘 특별히 못해서 C등급을 주었는지에 대한 서술이다.
사람이 평가 의견을 일일이 다 읽어 보고 요약할 수도 있지만 주관이 개입될 소지가 크다.
TF: Term Frequency
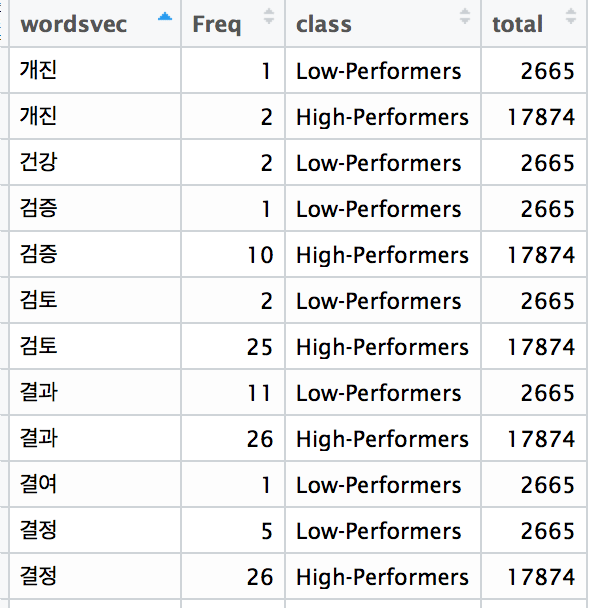
문서를 정량적으로 이해하기 위해 가장 먼저 할 수 있는 일은 특정 문서를 구성하는 단어와 해당 단어의 출현빈도로 정리하는 것이다. 특정 문서에서 특정 단어가 얼마나 빈번히 사용되었는지를 측정하는 지표를 tf(term frequency)라고 한다.
예를 들면, 고성과자의 평가의견으로 구성된 문서(class=high-performers)와 저성과자의 평가의견으로 구성된 문서(class=low-performers) 각각에서 추출한 단어(wordsvec)와 해당 단어의 빈도(Freq)로 구성된 테이블을 아래처럼 만들 수 있다.
total은 해당 class 문서에서 추출된 단어들의 빈도를 모두 더한 총합이며 tf=freq/total이 된다
IDF: Inverse Document Frequency
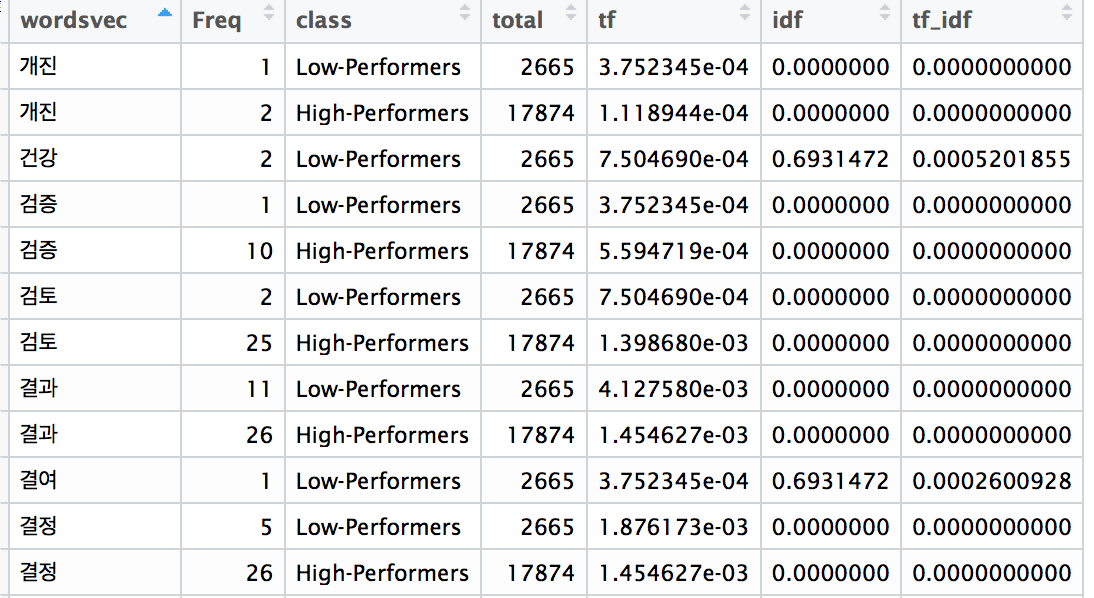
문서를 정략적으로 이해하는데 요긴한 또 다른 지표로는 단어의 idf(inverse document frequency)가 있다. idf는 해당 단어가 다른 문서들에서는 잘 사용되지 않은 경우 증가하게 된다. idf는 해당 단어가 문서의 특징을 얼마나 잘 나타내주는지에 대한 척도라고 생각할 수 있다.
특정 단어의 idf 값은 총문서의 갯수를 해당 단어가 포함된 문서의 갯수로 나눈 값에 대한 자연로그 값이다. (아래그림 참고)
총 문서의 갯수=2와 해당 단어가 나온 문서의 갯수=2가 같은 경우 idf = ln1 = 0
총 문서의 갯수=2, 해당 단어가 나온 문서의 갯수=1인 경우 idf = ln2 = 0.6931
Zipf’s law
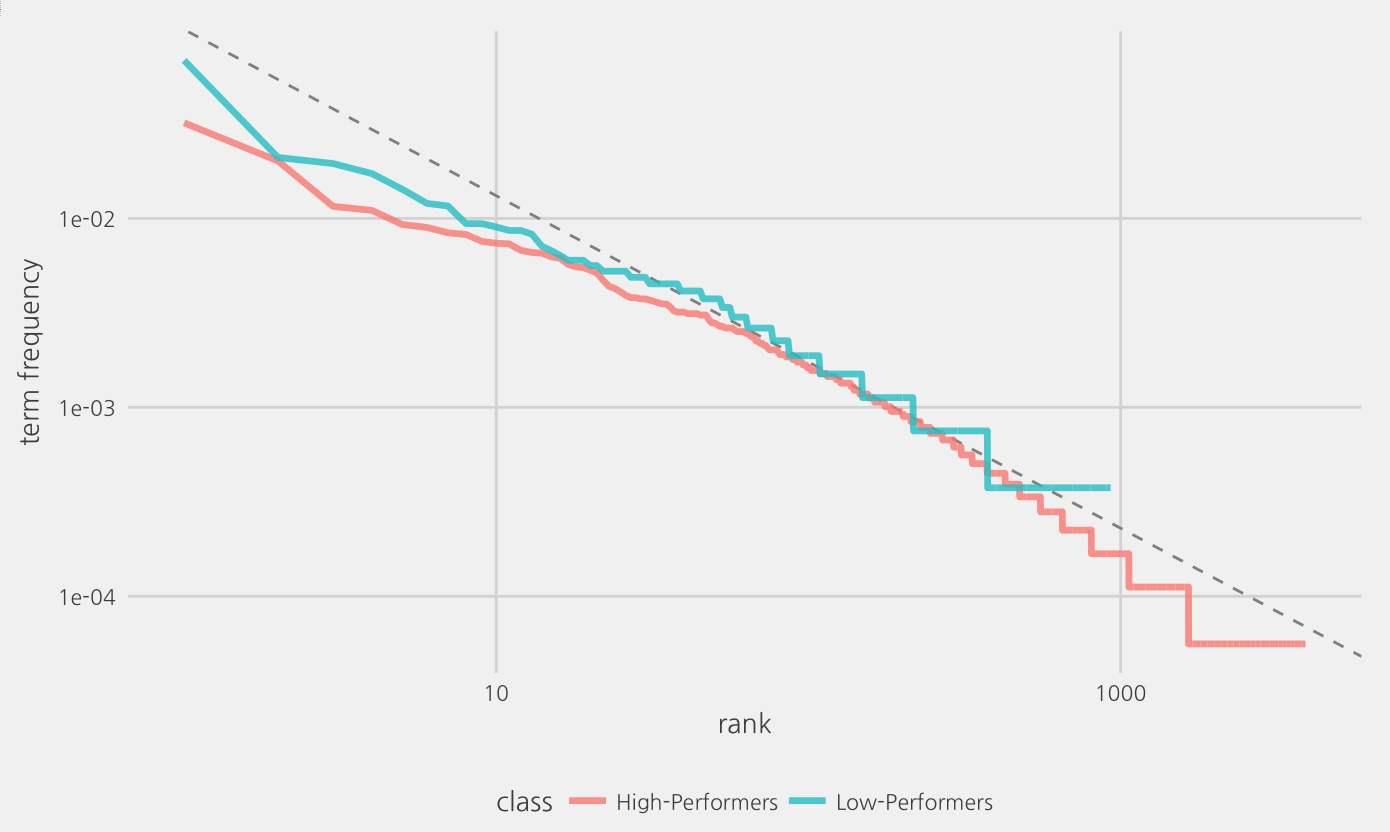
Zipf의 법칙이라는 것도 있는데 충분히 큰 문서(장편 소설, 성경책)에서 추출한 단어들의 (빈도) 랭킹과 빈도를 곱하면 동일한 값(상수)이 나오는 현상을 의미한다.
예를 들면, 빈도 수 ranking 1위인 단어의 사용 빈도가 1,000이었다면, 2위 단어의 빈도는 5,00,….500위 단어의 빈도는 2와 같은 식이다.
아래 그림(X, Y축 모두 로그 스케일 사용)에서 볼 수 있는 것처럼 평가 의견에 사용된 단어들도 지프의 법칙을 따르고 있다. 평가의견 문서에서도 제한된 수의 단어들이 문서의 대부분을 구성하고 있는 것이다.
나한테는 있고 너한테는 없는 것
우선 고성과자 저성과자 평가의견 문서에서 빈번하게 사용된 단어의 순위를 살펴보자. 사람의 어휘력, 언어 습관이 비슷해서 그런지 비슷하다.
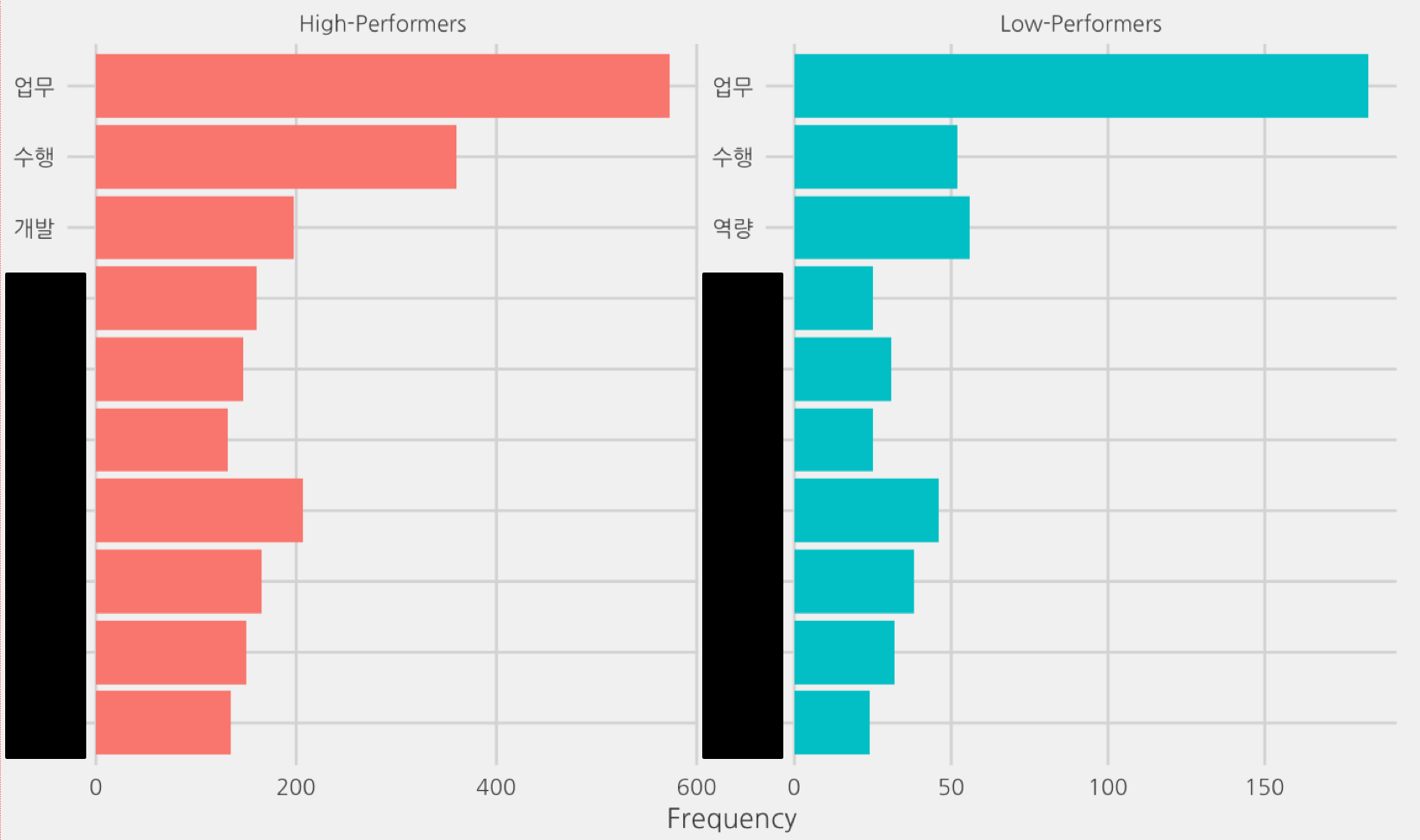
이번엔, 고성과자, 저성과자에 대한 평가의견 문서의 특성을 tf-idf 랭킹(내 문서에는 사용되었는데 네 문서에는 사용되지 않은 단어에 가중치를 준 단어의 빈도)을 통해 살펴보자.
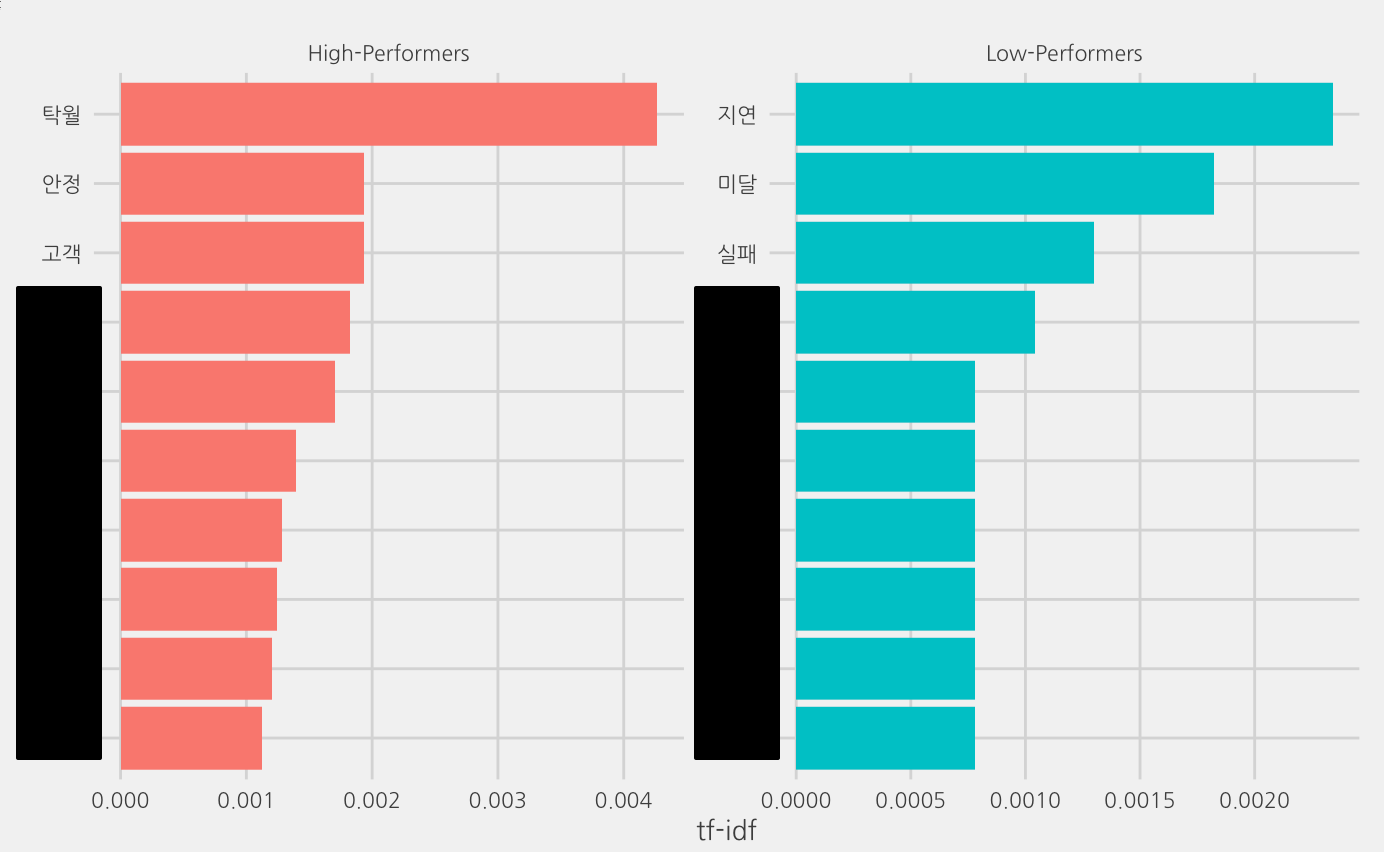
좀 뻔하지만 뭘 기대했는가? 그래도, 개별 단어의 빈도 정보를 가지고 이 정도 한 게 어딘가. 다음번 글에서는 단어 간의 관계를 통해 문서를 이해하는 방법을 다루겠다.
본 예제에서는 문서의 종류가 딱 두가지(고성과자 평가의견 묶음, 저성과자 평가의견 묶음)밖에 없었기 때문에 양쪽에 동시에 쓰인 단어는 idf값이 0이 되어 tf와 idf를 곱한 tf-idf값도 0이 된다.
tf-idf값을 사용하지 않고도 단어의 상대적 중요도를 계산할 수도 있다. 예를 들면 동일한 단어가 서로 다른 문서에서 차지한 랭킹의 차이를 활용할 수도 있다.