데이터로 은폐되었던 표절 찾기
미국 내 주요 일간지에 십자낱말 퍼즐(crossword puzzle)을 가장 왕성하게 공급해온 Timothy Parker라는 사람이 뉴욕타임즈의 십자낱말 퍼즐을 왕성하게 표절해온 사실이 최근 밝혀진 적이 있다.
수십만명이 넘는 골수 퍼즐 매니아들이 십년이 넘도록 알아채지 못 한 표절 사실을 밝혀낸 것은 바로 Saul Pwanson이라는 소프트웨어 엔지니어였다. 아마추어 십자낱말 퍼즐 제작자이기도 한 Pwanson은 52,000개의 십자낱말 퍼즐 데이터베이스를 - 취미로 - 구축한 후 유사한 퍼즐을 찾는 프로그램을 개발하여 분석 결과를 공개하였다.
십자낱말 퍼즐은 아래의 네가지 요소로 구성된다.
- The theme(테마): 퍼즐의 정체성을 구성하는 핵심 요소로서 퍼즐을 독창적으로 만들어준다. 퍼즐 제작자들이 창작의 과정에서 제일 어려워 하는 부분이기도 하다. 테마는 대개 퍼즐의 답변 중 가장 긴 답변들이며 테마 답변들은 서로 재치있게 연관되어 있다.
- The fill: (테마 답변을 제외한) 퍼즐의 (채워넣어야 하는) 나머지 답변들
- The grid: 퍼즐을 구성하는 희고 검은 사각형들
- The clues: 답변에 대한 단서
아래 그림[실제 표절 사례 중 하나]에서 제일 긴 세개의 답변을 보면 모두 Exasperate(화나게 하다)라는 뜻의 관용구들이며 이 답변들이 해당 퍼즐의 테마가 된다.
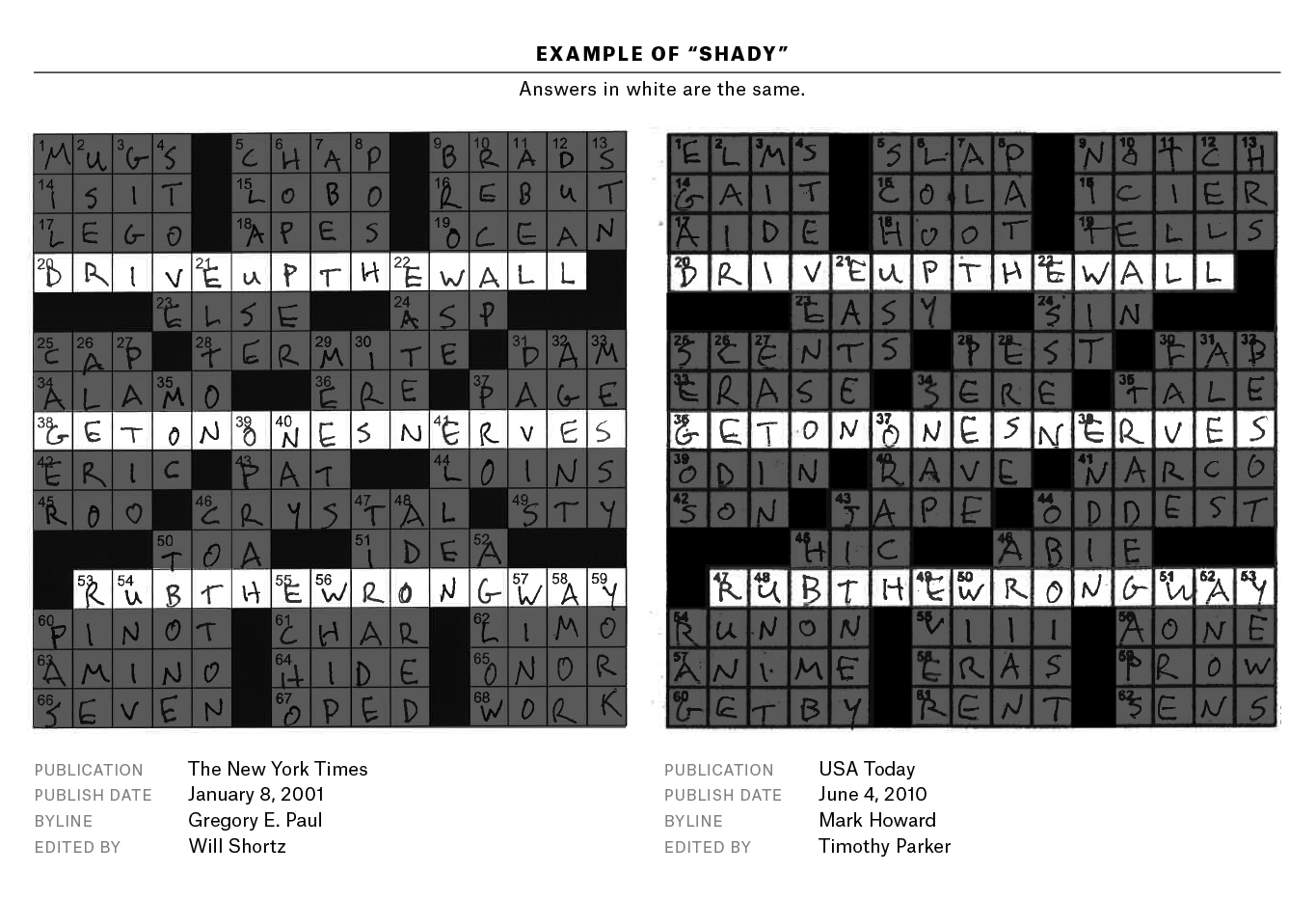
Pwanson은 퍼즐 간 Grid의 유사도(동일한 위치의 사각형에 담긴 내용의 유사도)와 답변의 유사도(위치와 무관하게 전체 답변 갯수 중 동일한 답변의 수)를 계산하였다. 아래 그림처럼 “A라는 퍼즐과 B라는 퍼즐은 Grid의 유사도 96%, 총 76개의 답변 중 71개가 일치"와 같은 식으로 두 퍼즐간의 유사성을 계산한 것이다.
(실제 표절 여부를 판단하는데는 테마의 유사성이 핵심적인 판단 기준이 될 거라고 생각한다. theme = puzzle’s identity)

2003년부터 USA Today에 실린 십자낱말 퍼즐의 16%가 그 이전에 제작된 퍼즐들과 최소 25% 이상 유사한 것으로 계산되었다고 한다.
"데이터를 모아 놓으면 보고 싶지 않은 것도 보게 된다.” Pwanson과 함께 프로그램 개발에 참여한 친구의 말이다. (사람이 기계에 지는 것도 자꾸 보게 되고 말이다.)
“I guess that’s the nature of any data set. You might find things you’d rather not see.”